
基础数据模型
xml json sql nosql(not only sql) 层次模型(tree 类json)—>关系模型(sql)、网状模型(CODASYL,每个记录可以有多个父节点,类似用指针连接,查找类似遍历链表 //弃用了)
查询语言
MapReduce
假设你是一名海洋生物学家,每当你看到海洋中的动物时,你都会在数据库中添加一条观察记录。现在你想生成一个报告,说明你每月看到多少鲨鱼。
在 PostgreSQL 中,你可以像这样表述这个查询:
date_trunc('month',timestamp) 函数用于确定包含 timestamp 的日历月份,并返回代表该月份开始的另一个时间戳。换句话说,它将时间戳舍入成最近的月份。这个查询首先过滤观察记录,以只显示鲨鱼家族的物种,然后根据它们发生的日历月份对观察记录果进行分组,最后将在该月的所有观察记录中看到的动物数目加起来。
同样的查询用 MongoDB 的 MapReduce 功能可以按如下来表述:
- 可以声明式地指定一个只考虑鲨鱼种类的过滤器(这是 MongoDB 特定的 MapReduce 扩展)。
- 每个匹配查询的文档都会调用一次 JavaScript 函数
map,将this设置为文档对象。
map函数发出一个键(包括年份和月份的字符串,如"2013-12"或"2014-1")和一个值(该观察记录中的动物数量)。
map发出的键值对按键来分组。对于具有相同键(即,相同的月份和年份)的所有键值对,调用一次reduce函数。
reduce函数将特定月份内所有观测记录中的动物数量相加。
- 将最终的输出写入到
monthlySharkReport集合中。
例如,假设
observations 集合包含这两个文档:对每个文档都会调用一次
map 函数,结果将是 emit("1995-12",3) 和 emit("1995-12",4)。随后,以 reduce("1995-12",[3,4]) 调用 reduce 函数,将返回 7。假设你是一名海洋生物学家,每当你看到海洋中的动物时,你都会在数据库中添加一条观察记录。现在你想生成一个报告,说明你每月看到多少鲨鱼。
在 PostgreSQL 中,你可以像这样表述这个查询:
date_trunc('month',timestamp) 函数用于确定包含 timestamp 的日历月份,并返回代表该月份开始的另一个时间戳。换句话说,它将时间戳舍入成最近的月份。这个查询首先过滤观察记录,以只显示鲨鱼家族的物种,然后根据它们发生的日历月份对观察记录果进行分组,最后将在该月的所有观察记录中看到的动物数目加起来。
同样的查询用 MongoDB 的 MapReduce 功能可以按如下来表述:
- 可以声明式地指定一个只考虑鲨鱼种类的过滤器(这是 MongoDB 特定的 MapReduce 扩展)。
- 每个匹配查询的文档都会调用一次 JavaScript 函数
map,将this设置为文档对象。
map函数发出一个键(包括年份和月份的字符串,如"2013-12"或"2014-1")和一个值(该观察记录中的动物数量)。
map发出的键值对按键来分组。对于具有相同键(即,相同的月份和年份)的所有键值对,调用一次reduce函数。
reduce函数将特定月份内所有观测记录中的动物数量相加。
- 将最终的输出写入到
monthlySharkReport集合中。
例如,假设
observations 集合包含这两个文档:对每个文档都会调用一次
map 函数,结果将是 emit("1995-12",3) 和 emit("1995-12",4)。随后,以 reduce("1995-12",[3,4]) 调用 reduce 函数,将返回 7。MapReduce 的一个可用性问题是,必须编写两个密切合作的 JavaScript 函数,这通常比编写单个查询更困难。此外,声明式查询语言为查询优化器提供了更多机会来提高查询的性能。基于这些原因,MongoDB 2.2 添加了一种叫做 聚合管道 的声明式查询语言的支持【9】。用这种语言表述鲨鱼计数查询如下所示:
聚合管道语言与 SQL 的子集具有类似表现力,但是它使用基于 JSON 的语法而不是 SQL 的英语句子式语法;这种差异也许是口味问题。这个故事的寓意是 NoSQL 系统可能会发现自己意外地重新发明了 SQL,尽管带着伪装。
图数据模型
Cypher查询
查找所有从美国移民到欧洲的人的 Cypher 查询:
查询按如下来解读:
找到满足以下两个条件的所有顶点(称之为 person 顶点):
person顶点拥有一条到某个顶点的BORN_IN出边。从那个顶点开始,沿着一系列WITHIN出边最终到达一个类型为Location,name属性为United States的顶点。
person顶点还拥有一条LIVES_IN出边。沿着这条边,可以通过一系列WITHIN出边最终到达一个类型为Location,name属性为Europe的顶点。对于这样的Person顶点,返回其name属性。
sql 图查询
- 首先,查找
name属性为United States的顶点,将其作为in_usa顶点的集合的第一个元素。
- 从
in_usa集合的顶点出发,沿着所有的with_in入边,将其尾顶点加入同一集合,不断递归直到所有with_in入边都被访问完毕。
- 同理,从
name属性为Europe的顶点出发,建立in_europe顶点的集合。
- 对于
in_usa集合中的每个顶点,根据born_in入边来查找出生在美国某个地方的人。
- 同样,对于
in_europe集合中的每个顶点,根据lives_in入边来查找居住在欧洲的人。
- 最后,把在美国出生的人的集合与在欧洲居住的人的集合相交。
三元组存储和 SPARQL
在三元组存储中,所有信息都以非常简单的三部分表示形式存储(主语,谓语,宾语)。例如,三元组 (吉姆, 喜欢, 香蕉)中,吉姆 是主语,喜欢是谓语(动词),香蕉 是对象。
三元组的主语相当于图中的一个顶点。而宾语是下面两者之一:
- 原始数据类型中的值,例如字符串或数字。在这种情况下,三元组的谓语和宾语相当于主语顶点上的属性的键和值。例如,
(lucy, age, 33)就像属性{“age”:33}的顶点 lucy。
- 图中的另一个顶点。在这种情况下,谓语是图中的一条边,主语是其尾部顶点,而宾语是其头部顶点。例如,在
(lucy, marriedTo, alain)中主语和宾语lucy和alain都是顶点,并且谓语marriedTo是连接他们的边的标签。
RDF模型 使用Turtle 语言是一种用于 RDF 数据的人类可读格式
SPARQL 查询语言
SPARQL 是一种用于三元组存储的面向 RDF 数据模型的查询语言【43】(它是 SPARQL 协议和 RDF 查询语言的缩写,发音为 “sparkle”)。SPARQL 早于 Cypher,并且由于 Cypher 的模式匹配借鉴于 SPARQL,这使得它们看起来非常相似【37】。
与之前相同的查询 - 查找从美国转移到欧洲的人 - 使用 SPARQL 比使用 Cypher 甚至更为简洁
与之前相同的查询 - 查找从美国转移到欧洲的人 - 使用 SPARQL 比使用 Cypher 甚至更为简洁。
相同的查询,用 SPARQL 表示
结构非常相似。以下两个表达式是等价的(SPARQL 中的变量以问号开头):
因为 RDF 不区分属性和边,而只是将它们作为谓语,所以可以使用相同的语法来匹配属性。在下面的表达式中,变量
usa 被绑定到任意具有值为字符串 "United States" 的 name 属性的顶点:CODASYL与图数据库不同
- 在 CODASYL 中,数据库有一个模式,用于指定哪种记录类型可以嵌套在其他记录类型中。在图形数据库中,不存在这样的限制:任何顶点都可以具有到其他任何顶点的边。这为应用程序适应不断变化的需求提供了更大的灵活性。
- 在 CODASYL 中,达到特定记录的唯一方法是遍历其中的一个访问路径。在图形数据库中,可以通过其唯一 ID 直接引用任何顶点,也可以使用索引来查找具有特定值的顶点。
- 在 CODASYL,记录的后续是一个有序集合,所以数据库的人不得不维持排序(这会影响存储布局),并且插入新记录到数据库的应用程序不得不担心的新记录在这些集合中的位置。在图形数据库中,顶点和边不是有序的(只能在查询时对结果进行排序)。
- 在 CODASYL 中,所有查询都是命令式的,难以编写,并且很容易因架构中的变化而受到破坏。在图形数据库中,如果需要,可以在命令式代码中编写遍历,但大多数图形数据库也支持高级声明式查询语言,如 Cypher 或 SPARQL。
基础:Datalog
Datalog是比 SPARQL、Cypher 更古老的语言
在实践中,Datalog 被用于少数的数据系统中:例如,它是 Datomic 的查询语言,Cascalog 是一种用于查询 Hadoop 大数据集的 Datalog 实现 。
Datalog 的数据模型类似于三元组模式,但进行了一点泛化。把三元组写成 谓语
(主语,宾语),而不是写三元语(主语,谓语,宾语) 示例显示了如何用 Datalog 写入我们的例子中的数据
用 Datalog 表示
Cypher 和 SPARQL 使用 SELECT 立即跳转,但是 Datalog 一次只进行一小步。我们定义 规则,以将新谓语告诉数据库:在这里,我们定义了两个新的谓语,
within_recursive 和 migrated。这些谓语不是存储在数据库中的三元组中,而是它们是从数据或其他规则派生而来的。规则可以引用其他规则,就像函数可以调用其他函数或者递归地调用自己一样。像这样,复杂的查询可以一次构建其中的一小块。在规则中,以大写字母开头的单词是变量,谓语则用 Cypher 和 SPARQL 的方式一样来匹配。例如,
name(Location, Name) 通过变量绑定 Location = namerica 和 Name ='North America' 可以匹配三元组 name(namerica, 'North America')。要是系统可以在
:- 操作符的右侧找到与所有谓语的一个匹配,就运用该规则。当规则运用时,就好像通过 :- 的左侧将其添加到数据库(将变量替换成它们匹配的值)。因此,一种可能的应用规则的方式是:
- 数据库存在
name (namerica, 'North America'),故运用规则 1。它生成within_recursive (namerica, 'North America')。
- 数据库存在
within (usa, namerica),在上一步骤中生成within_recursive (namerica, 'North America'),故运用规则 2。它会产生within_recursive (usa, 'North America')。
- 数据库存在
within (idaho, usa),在上一步生成within_recursive (usa, 'North America'),故运用规则 2。它产生within_recursive (idaho, 'North America')。
通过重复应用规则 1 和 2,
within_recursive 谓语可以告诉我们在数据库中包含北美(或任何其他位置名称)的所有位置。这个过程如 图 2-6 所示。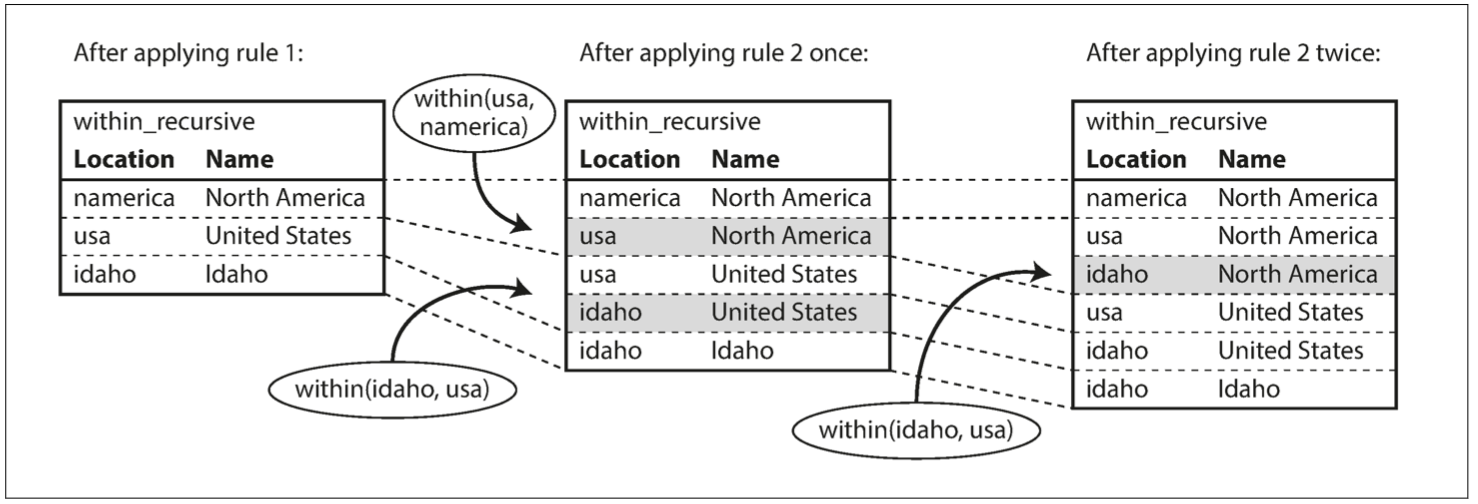
图 2-6 使用示例 2-11 中的 Datalog 规则来确定爱达荷州在北美。
现在规则 3 可以找到出生在某个地方
BornIn 的人,并住在某个地方 LivingIn。通过查询 BornIn ='United States' 和 LivingIn ='Europe',并将此人作为变量 Who,让 Datalog 系统找出变量 Who 会出现哪些值。因此,最后得到了与早先的 Cypher 和 SPARQL 查询相同的答案。相对于本章讨论的其他查询语言,我们需要采取不同的思维方式来思考 Datalog 方法,但这是一种非常强大的方法,因为规则可以在不同的查询中进行组合和重用。虽然对于简单的一次性查询,显得不太方便,但是它可以更好地处理数据很复杂的情况。